지난 6월 말, ChatGPT의 개발사인 OpenAI가 비평적인 언어 모델인 CriticGPT 모델을 개발했습니다. 인간보다 더 뛰어난 비판 능력을 보유했다는데요. 정말인지 살펴볼까요? 🧐
CriticGPT 파헤치기
ChatGPT의 근간이 된 모델은 바로 InsturctGPT입니다. 이 모델은 LLM이 인간의 지시 사항(Instruction)을 이해하도록 학습시키는 방법으로, LLM이 가진 지식을 기반으로 인간처럼 ‘대화’할 수 있게 개발됐습니다. 이때 사용된 학습 방법이 바로 RLHF(Reinforcement Learning from Human Feedback)입니다. 인간의 피드백에 따라 더 높은 선호도를 보이는 답변을 생성하도록 학습시켰죠.
하지만 이 방식은 내용상의 오류를 쉽게 발견하기 어렵다는 단점이 있습니다. 인간은 정확도보다 형식에 초점을 맞추는 경우가 많습니다. 더 길고 자세한 것처럼 보이는 글이 인간의 더 높은 선호도를 받을 위험이 있죠. 그 과정에서 세세한 오류들을 놓치기 쉽다보니 RLHF 방식이 환각 현상의 원인으로 지목되기도 합니다.
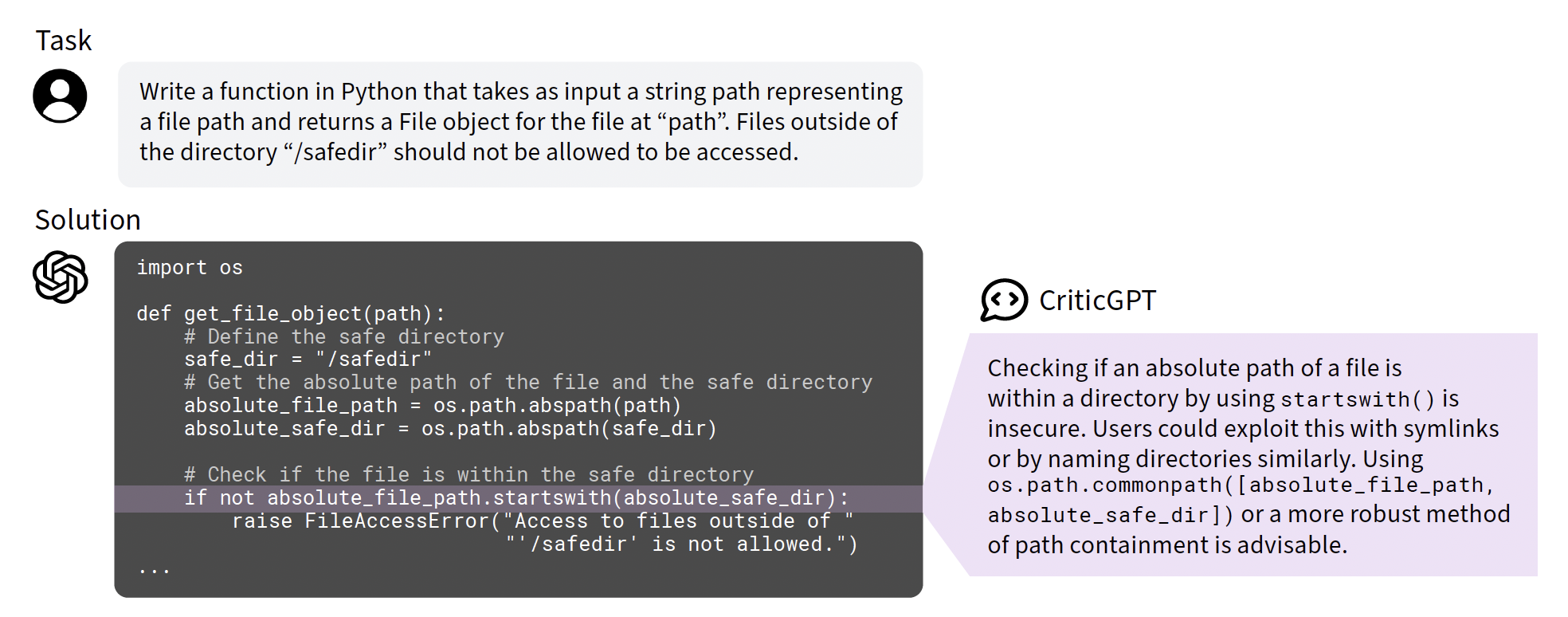
OpenAI는 <LLM Critics Help Catch LLM Bugs> 논문에서 해당 문제를 지적하며 CriticGPT를 발표했습니다. 연구진은 LLM이 생성한 코드 상의 작은 오류들을 발견하고 그 이유에 대해 답할 수 있는 모델을 개발하고자 했습니다.
LLM 비평가(Critics)는 InstructGPT와 유사한 AutoRegressive 구조지만, 질문과 답변 쌍을 입력받아 자연어 ‘비평’을 작성합니다. 이때 출력하는 비평의 구조는 답변에서 인용한 부분에 주석을 다는 형태로, 어느 부분이 어떻게 틀렸는지 정확하게 지적합니다.
LLM 비평가 CriticGPT가 인용구를 작성한 예시 출처: <LLM Critics Help Catch LLM Bugs> (McAleese et al., 2024)
어떤 비판은 잘못된 내용에 대해서 상세하게 이유를 설명하지만, 작은 오류가 있을 수 있습니다. 반면, 제대로 설명하진 않지만 정확하게 틀린 부분을 지적’만’ 할 수도 있지요. 좋은 비판은 이 둘을 모두 포함할 텐데요. 더 좋은 비판을 만들기 위해서는 우선 비판에 대한 적절한 평가 기준이 설정되어야 합니다. 연구진이 제시한 네 가지 평가 기준은 다음과 같습니다.
오류와 관련된 질의는 크게 두 가지 종류로 볼 수 있습니다.
1. 무엇이 오류인지 모른 채 코드만 보고 오류를 발견하는 경우입니다. “이런 코드를 작성했는데 오류가 있는지 알려줘”와 같은 질문 형식이 되겠죠. 이는 우리가 기본적으로 코드를 전부 작성했다는 전제가 필요합니다.
2. 어떤 코드를 실행하고 보니 오류가 발생했습니다. “이 코드를 실행했더니 어떠한 오류가 발생했어. 어떻게 고쳐야 하는지 알려줘”와 같이 질문할 수 있겠죠. 이때 언어 모델은 적어도 어떤 문제 때문에 오류가 발생했는지 파악할 수 있습니다.
언어 모델이 더욱 자연스럽게 접할 수 있는 질문은 2번입니다. 하지만 CriticGPT의 목표는 더 많은 오류를 잘 발견하고 평가하는 데 있습니다. 결국 어떤 데이터를 학습시켜야 이를 잘 달성할 수 있는지 파악해야 하는데요. 이를 위해서는 1번과 같은 요소를 활용하는 게 더 도움이 될 수 있습니다.
연구진은 사람들에게 ChatGPT가 생성한 답변에 일부러 작은 버그들을 심고, 그 버그에 대해서 설명하도록 했습니다. 이로써 고품질의 평가 데이터를 얻을 수 있었습니다.
CriticGPT를 학습시키기 위한 데이터 생성 과정 출처: <LLM Critics Help Catch LLM Bugs> (McAleese et al., 2024)
CriticGPT, 성능은 좋을까?
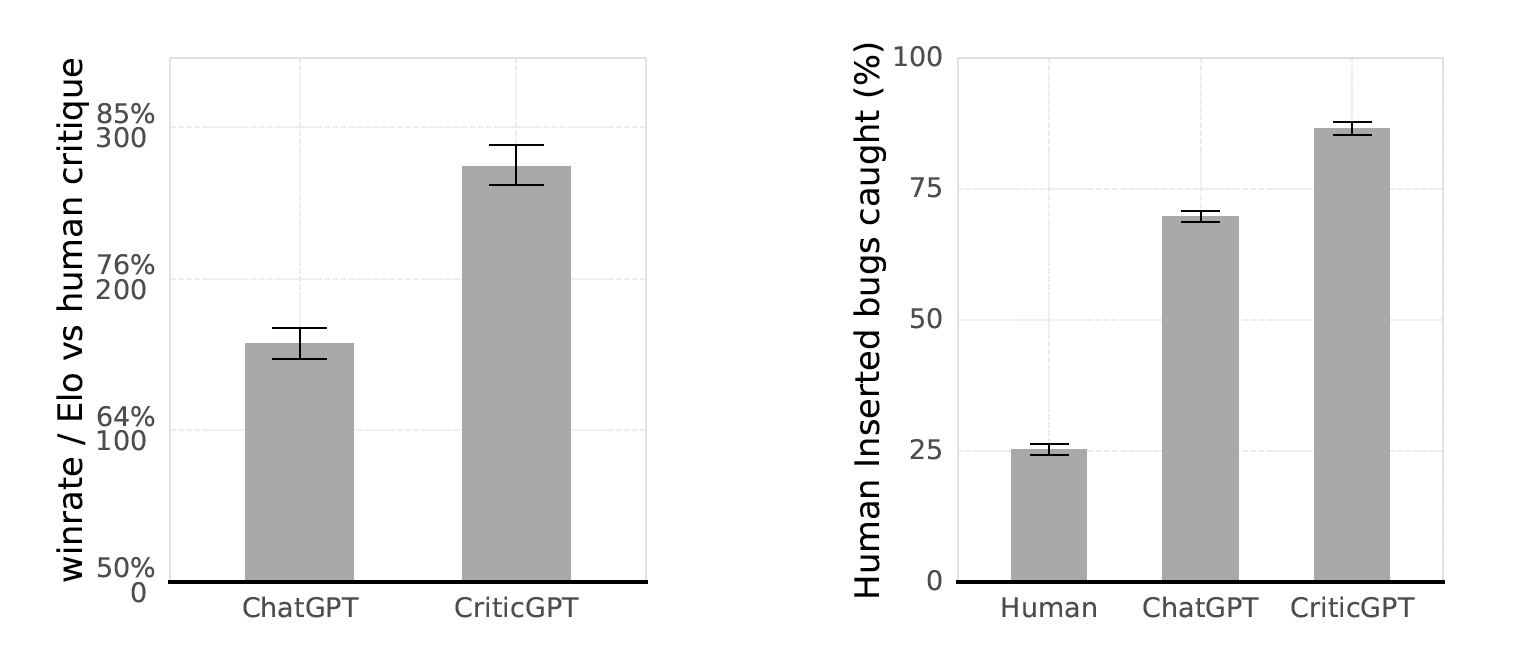
CriticGPT의 성능 비교 출처: <LLM Critics Help Catch LLM Bugs> (McAleese et al., 2024)
CirticGPT의 비평은 기존 ChatGPT의 비평에 비해 더욱 선호된다는 결과입니다. 심지어 인간의 평가보다도 선호되는 경향이 나타나기도 했는데요. 버그에 대한 탐지 수준도 높았습니다. 인간이 삽입한 오류를 발견하는 문제에 대해서 인간은 4개 중 1개꼴로 정답을 맞히는 수준이지만, ChatGPT는 약 70%, CriticGPT는 90%에 육박하는 정도의 수준으로 정답을 맞혔습니다!
흥미롭게도 CriticGPT는 코드를 기반으로 오류를 발견하도록 만들어졌지만, 실제로는 코드가 아닌 데이터에 대해서 오류를 더욱 잘 발견합니다. 덕분에 ChatGPT 학습 데이터에 대해서도 오류를 수정할 수 있었다는데요. 코드를 기반으로 생성했으나, 일반적인 데이터에 대해서도 성능이 개선됐다니, 코드를 기반으로 오류가 발생하는 원리에 대해 깨우친 것일까요? 😳
: 오는 10일, 삼성전자가 2024년 파리에서 'Galaxy Unpacked' 행사를 개최합니다. 주요 제품으로는 갤럭시 Z 폴드와 갤럭시 Z 플립 등의 새로운 폴더블 스마트폰이 중심이 될 것으로 보이는데요. 갤럭시 AI에 대한 발표와 새로운 웨어러블 기기인 갤럭시 링, 갤럭시 버즈에 대한 정보도 공개될 예정입니다. 새로운 모델은 퀄컴의 스냅드래곤 8 세대 3 프로세스를 탑재한답니다.
: OpenAI와 마이크로소프트(MS)가 소유한 GitHub가 인공지능(AI) 코딩 보조툴 'Copilot'과 관련된 첫 저작권 소송에서 승리했습니다. 프로그래머들은 코파일럿이 오픈 소스 코드를 불법적으로 사용했다고 주장했으나, 샌프란시스코 연방법원은 구체적인 피해 내용을 입증하지 못했다며 소송을 기각했습니다. 이번 소송은 생성 AI가 훈련 데이터로 사용하는 공개 자료의 저작권 문제와 관련이 깊어 주목받고 있습니다.
: 에릭슨 컨슈머랩은 2030년대에 소비자 80%가 인공지능(AI)을 사용해 중요한 결정을 내릴 것이라고 전망했습니다. 이 조사는 전 세계 13개 도시의 6500여 명의 얼리어답터를 대상으로 진행되었는데요. 응답자 중 51%는 AI에 대해 희망적인 반응을 보였으며, 34%는 두려움을 느꼈다고 답했습니다.