💫 놓치면 안되는 이번주 AI 소식 TOP 3 글: 이성배, 딥다이브(deep daiv.) 제휴 콘텐츠 ㅣ 에디터: 정인영 |
|
|
지난달 29일, Meta가 SAM(Segment Anything Model) 2를 공개했습니다. 2023년 4월, SAM을 처음 선보인 뒤로 1년 4개월만인데요. 얼마나 달라졌는지 살펴볼까요? 🧐
|
|
|
SAM은 그 이름처럼 어떤 것이든 분할(Segment Anything)을 목표로 합니다. 여기서 분할(Segmentation)이란, 배경과 다른 사물을 구분해 특정한 객체의 영역을 찾아내는 것입니다. 화상 회의에서 내 배경을 제거하는 기능을 떠올리면 쉽게 이해할 수 있습니다.
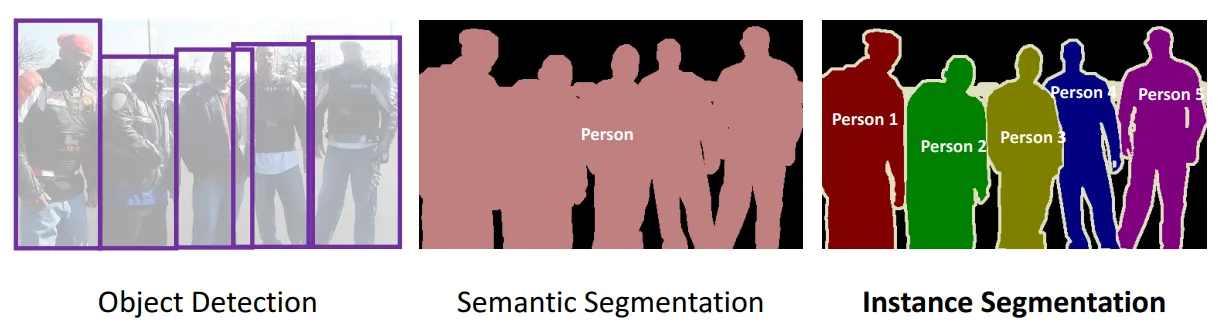
이를 위해서는 객체 단위를 나누는 기준이 명확해야 합니다. 또한 기준에 따라 Segmentation 태스크를 더욱 세부적으로 구분하는데요. 아래 이미지와 같이 의미 단위(e.g. 사람들 전체)로 분할하기도 하고, 인스턴스 단위(e.g. 한 사람씩)으로 구분하는 등 목표에 따라 분할 방법이 달라질 수 있습니다.
|
|
|
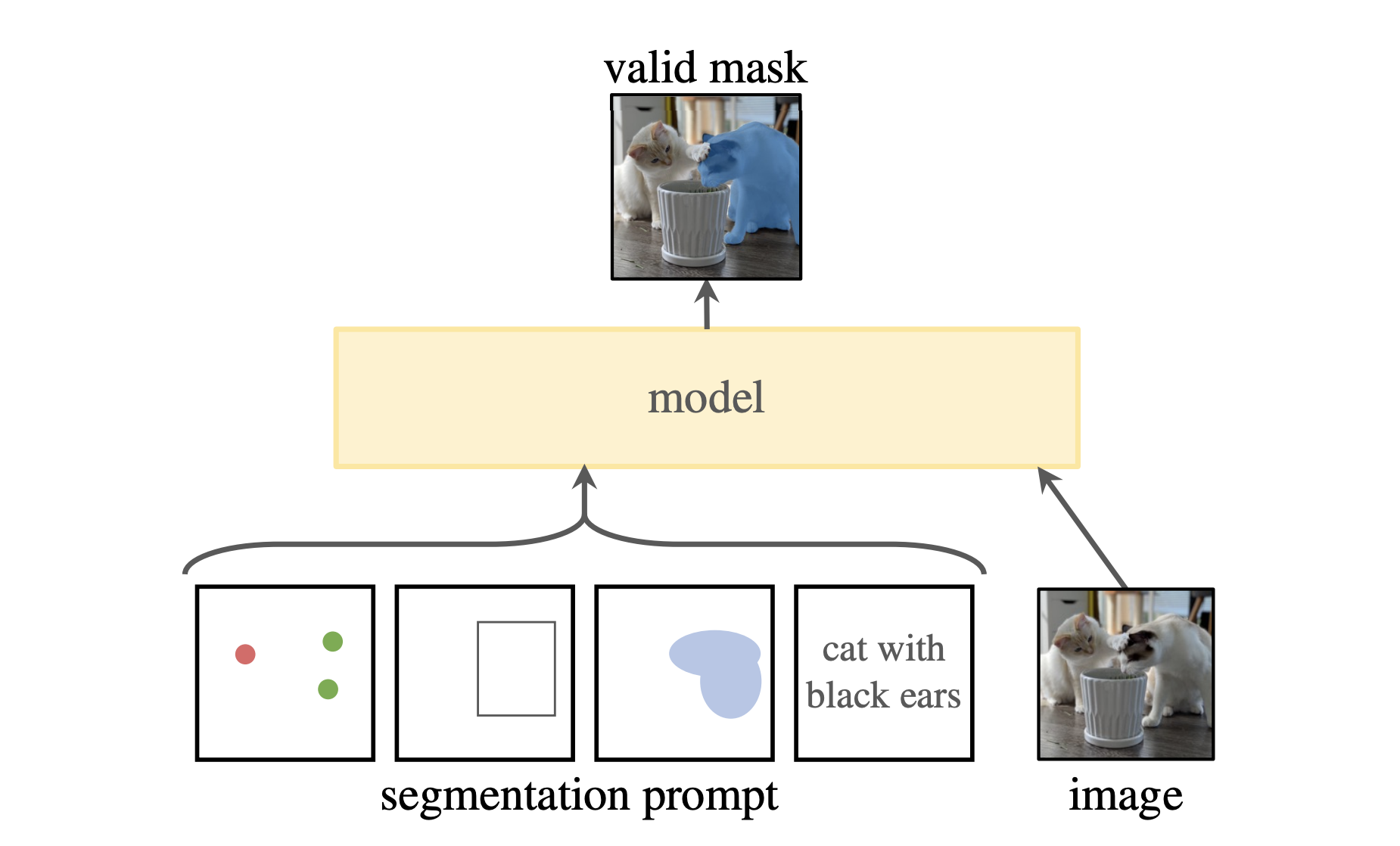
다양한 Segmentation Prompt 예시. 출처: <Segment Anything> (Kirillov et al., 2023)
분할 태스크의 어려운 점은 바로 모호성(Ambiguity)에 있습니다. 아무리 프롬프트를 입력 받는다고 하더라도, 하나의 점 또는 마스크 영역만으로는 정확히 무엇을 원하는지 알기 어려울 수 있기 때문인데요. 예를 들어, 사람 이미지에 옷을 클릭했다면 사람을 선택한 것인지, 아니면 옷 자체를 선택한 것인지 파악이 어려울 수 있습니다. SAM은 이런 문제를 해결하기 위해서 하나의 입력값에 대해서 그 입력을 포함하는 여러 대상(전체(Whole), 부분(Part), 부분 내 영역(Subpart))을 예측하도록 개발했다는 특징이 있습니다.
|
|
|
전체(Whole) , 부분(Part) , 부분 내 영역(Subpart)을 예측해 결과를 제시하는 SAM.
출처: <Segment Anything> (Kirillov et al., 2023)
|
|
|
SAM 2는 어떤 점이 달라졌을까요? 이번 SAM 2를 다룬 논문의 제목을 살펴보면 그 답을 알 수 있습니다. <SAM 2: Segment Anything in Images and Videos>. 이제 비디오에서도 분할이 가능해졌습니다.
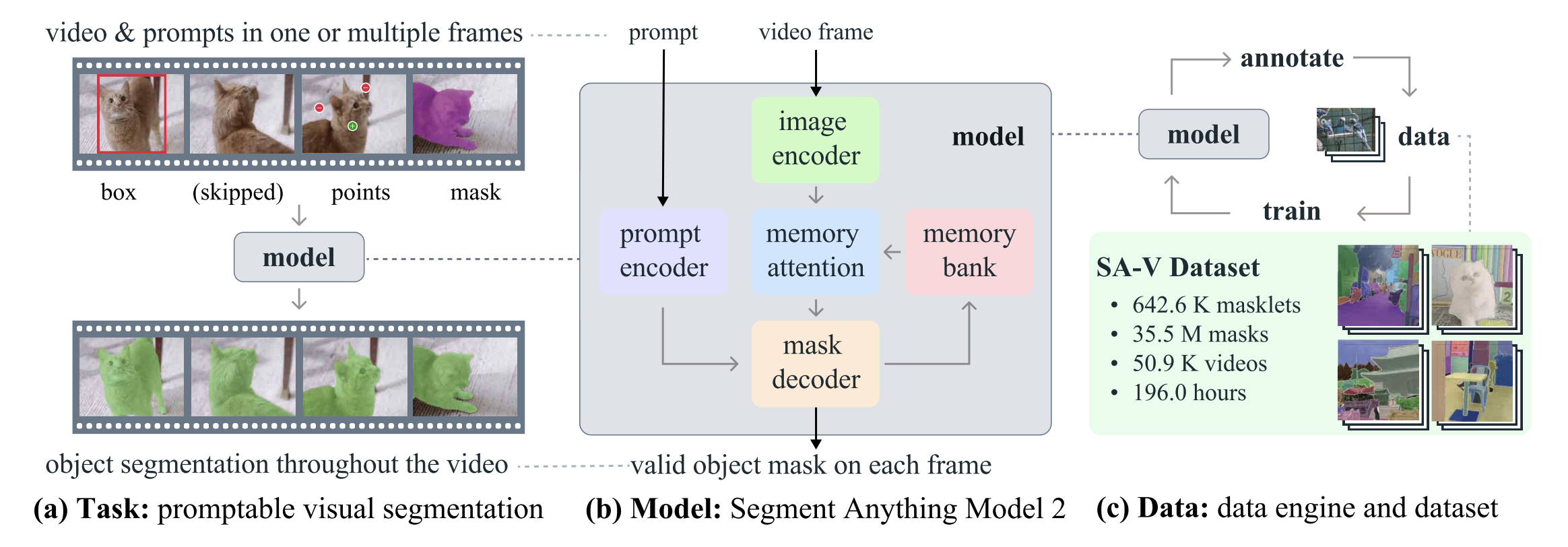
비디오는 단순히 이미지의 합으로 보긴 어렵습니다. 비디오는 이미지와 달리 ‘시간’이라는 새로운 축이 필요합니다. 그리고 동일한 대상에 대해서 ‘시간’이 흐르더라도 일관되게 객체를 분할해야 하기 때문에 훨씬 난도 높은 과제이지요. 먼저 SAM 2의 전체적인 구조를 살펴보겠습니다. |
|
|
영상 데이터에 대해서 박스, 포인트, 마스크 등의 정보가 프롬프트로 입력됩니다. 그리고 이미지 인코더와 프롬프트 인코더로 구성된 모델에 이 정보 프롬프트를 입력하고, 마스킹 영역을 디코딩하는 식입니다.
이번 모델에서 변경된 부분 역시 이 비디오에서 마스크를 예측하는 데 특화되어 있습니다. 모델 이미지를 살펴보면 Memory Attention, Memory Bank가 눈에 띄는데요. Memory Attention은 현재 프레임의 특징을 이전 프레임의 특징 및 예측값과 결합하고, Memory Bank는 비디오에서 타깃 객체의 과거 예측 정보를 저장하는 역할을 합니다. 앞서 말씀드린 것처럼 비디오에서 시간에 따른 일관성은 중요합니다. 이를 유지하기 위해서 연구진은 다음 프레임의 마스크를 예측할 때, 이전 프레임의 정보를 같이 주입하도록 모델 구조를 설계했습니다.
|
|
|
642.6K의 Masklets(영상 속 박스, 포인트 등의 프롬프트 정보)와 35.5M개의 마스크, 50.9K개의 비디오로 구성된 대량의 데이터셋을 구축하기 위해 Meta는 자체적인 데이터 엔진을 활용했습니다. SAM 2의 데이터 엔진은 총 3단계로 구분됩니다.
1. 첫 번째 단계는 SAM을 개발하면서 제안한 데이터 엔진의 도움을 받아서 인간 작업자가 직접 레이블링하는 과정입니다. 시간과 비용이 많이 들지만 양질의 데이터를 확보할 수 있습니다.
2. 다음 단계에서는 SAM 2를 추가하여 SAM 2 Mask 버전을 사용했습니다. 여기서는 마스크만을 프롬프트로 사용하는데요. 작업자는 1단계에서처럼 SAM을 사용해 마스크를 그린 후 SAM 2 Mask를 통해 마스크를 영상 속 다른 프레임으로 전달합니다. 영상 속 시간 축에 따라서 비슷한 결과를 생성해야 하기 때문입니다. 이후 프레임에서는 SAM과 ‘브러시 및 ‘지우개’ 도구를 사용해 마스크를 수정하고, 이를 SAM 2 Mask에 피드백하여 더 정확한 마스크를 만듭니다. 일종의 SAM 2의 데이터 생성 및 학습 루프를 개발한 것입니다.
3. 마지막 단계에서는 완전한 기능을 갖춘 SAM 2를 사용했습니다. 이 단계에서는 작업자가 중간 프레임에서 수정이 필요한 경우만 클릭해 주면 됩니다. SAM 2를 사용하여 처음부터 다시 주석 달 필요 없이 마스크를 편집할 수 있습니다. 이로써 양질의 데이터셋을 많이 확보하고 비디오의 마스킹 방법까지 학습하나 SAM 2가 탄생할 수 있었습니다.
|
|
|
이미지 분할의 기반 모델이 됐던 SAM이 한 번 더 진화해 이제 비디오까지 평정했습니다. SAM으로 파생된 연구가 다양했던 만큼, 이번 SAM 2의 파급력 또한 클 것으로 보이는데요. 일상 생활 속 영상 편집 기술이나 영상 모달리티를 다루는 연구에서 다양한 발전을 기대하겠습니다. 🌟
|
|
|
업계 종사자들을 위한 밀도 높은 네트워킹 시간, AI Ignite가 돌아왔습니다!
21일(수), 홍콩과기대(HKUST) 겸임교수이자 전 하나금융지주 그룹데이터총괄인 황보현우님이 AI Ignite를 찾아오십니다.
현우님은 영국 케임브리지 국제인명센터(IBC)로부터 ‘빅데이터, 인공지능 분야 세계 100인의 전문가’에 선정된 데이터 사이언스 분야의 세계적인 전문가입니다.
현우님과 함께 <AI 시대의 경쟁우위 전략>에 대해 이야기 나누러 오세요!
|
|
|
: Meta가 오픈 소스 인공지능 모델 'Llama 3.1'을 출시했습니다. Llama 3.1이 대규모 다중작업 언어 이해(MMLU)에서 OpenAI의 GPT-4o 및 Anthropic의 Claude 3.5 Sonnet를 능가했다는데요. 이번 Llama 3.1은 3가지 버전으로, 가장 큰 버전은 4050억 개(405B)의 매개변수를 가지고 있습니다.
EU, 세계 최초 AI 법안 발효
: 유럽연합(EU)은 인간의 기본권을 보호하고 AI의 신뢰성을 보장하기 위해 세계 최초로 포괄적인 AI 규제법을 지난 1일부터 시행했습니다. 셀렉트스타도 이 주제를 다루었지요! ChatGPT, Claude 3.5 등의 범용 AI는 투명성을 확보하기 위해 학습 데이터를 명시해야 하며, 규정을 위반할 경우 최대 7%의 과징금이 부과됩니다. 전면 시행은 2026년 8월 예정입니다.
OpenAI, SearchGPT 발표
: OpenAI가 SearchGPT를 발표했습니다. 사용자의 질문에 대해 요약된 검색 결과와 소스 링크를 제공하며, 후속 질문과 상황에 맞는 응답이 가능합니다. 현재는 일부 사용자에게만 프로토타입 버전이 제공되며, 향후 ChatGPT와의 통합될 계획입니다.
|
|
|
The Data-centric AI company
|
|
|
|
📋 사업 및 제휴 문의 contact@selectstar.ai
📨 콘텐츠 및 행사 문의 marketing@selectstar.ai
|
|
|
|
|