물어보는 모든 것을 대답해주는 AI가 세상에 공개됐습니다. 그동안 많은 QA(Question&Answering) 인공지능이 있었지만 성능이 썩 좋지 못하거나, 윤리적인 문제에 휘말리곤 했습니다. 그런데 이번에 공개된 ChatGPT는 다릅니다. 데모를 직접 활용해본 사용자들은 말 그대로 ‘깜짝 놀랐다’고 표현을 했는데요. 도대체 무엇이길래 이렇게까지 주목하고 있는지, 이번 아티클에서는 ChatGPT를 소개합니다.
OpenAI는 지난 11월 30일, GPT 3.5을 기반으로 학습한 QA모델 ChatGPT를 선보였습니다. GPT 3.5는 간단하게 요약하면 GPT를 거듭 발전시켜 만든 모델로, 트랜스포머(Transformer)의 디코더(Decoder) 블럭을 활용해 문장 생성에 특화된 모델입닌다.
ChatGPT는 Transformer를 기반으로 하는 GPT의 특성상 입력값에 따른 적절한 출력값을 잘 해냅니다. 그래서 학습을 거듭하면 주어진 질문을 이해하고 그에 대한 적절한 대답을 생성할 수 있습니다.
하지만 이전까지의 GPT 모델은 학습시킨 데이터에 따라 다른 결과물이 출력되기에 성능이 떨어지거나 부적절한 답변을 생성하기도 했습니다. 학습 데이터에 항상 건전하고 올바른 내용만 있는 것은 아니기 때문입니다.
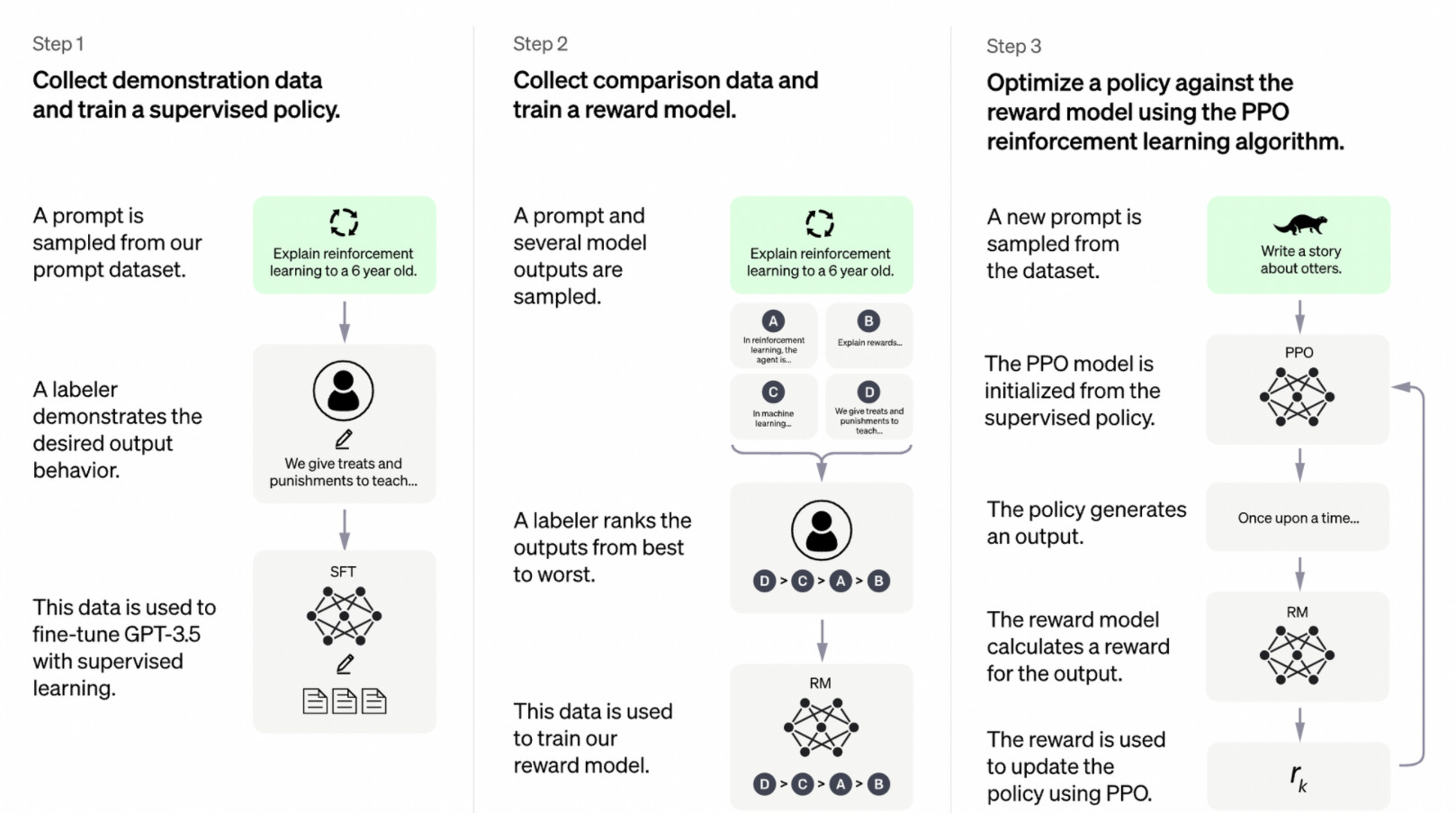
그래서 OpenAI는 새로운 방법을 도입합니다. 바로 RLHF(Reinforcement Learning from Human Feedback)입니다. 직역하면 인간 피드백 강화학습인데요, 지도학습으로 미세조정(파인튜닝)한 초기 모델에 인간이 개입하여 직접 피드백을 제공하는 방법입니다.
다소 강화학습 개념이 생소할 수 있겠습니다. 뜻밖에도 강화(Reinforcement)라는 개념은 심리학에서 기원합니다. 심리학에서 말하는 강화란, 보상(또는 처벌)을 제공함으로써 특정 행동을 하도록 (또는 하지 않도록) 하는 것입니다. 예를 들어, 청소를 한 학생에게 숙제 면제권을 준다면 너도 나도 교실 청소를 하려고 하겠지요. 숙제 면제권이라는 보상을 활용하여 청소라는 특정 행동을 강화시킨 셈입니다.
이처럼 강화학습에서는 행동(Act)에 따른 보상(Reward)을 주어 원하는 결과를 얻도록 합니다. 이때 주어진 환경에서 어떻게 행동할지 결정할 정책(Policy)이 필요하기도 합니다. 전통적인 강화학습은 딥러닝과 별개의 영역이었는데요, 보상을 극대화하기 위한 예측 과정에 딥러닝이 활용되기 시작했습니다.
이제 강화학습이 적용된 ChatGPT의 원리를 하나씩 알아보겠습니다.