All in One AI 데이터 솔루션 All in One
AI DATA SOLUTION-
SELECTSTAR |
|
|
최근 대화형 AI 경쟁이 치열합니다. 이런 대화형 AI는 잘 학습된 언어 모델을 대화를 목적으로 추가 학습시킨 것입니다. 가령 오픈 AI의 ‘ChatGPT’는 GPT-3.5, 구글 ‘Bard’는 LaMDA를 기반으로 학습한 것이지요. 많은 AI 기업들이 자신들만의 기술력이 반영된 언어 모델을 구축하는 데 심혈을 기울이고 있습니다. 이 경쟁에 Meta도 뛰고 있다는걸 지난달말 새로운 언어 모델, LLaMA를 공개하면서 뒤늦게나마 세상에 알렸습니다. LLaMA는(Large Language Model Meta AI)의 의미로 Meta의 AI 모델 이름이지만 스페인어로 "~로 불리다)의 뜻이 있습니다. Meta 연구진은 LLaMA 모델 성능을 GPT-3, Chinchilla, PaLM 등과 비교해 설명합니다. 특히, LLaMA-13B 모델이 GPT-3(175B) 모델에 비해 더 나은 성능을 보인다고 강조합니다. LLaMA에는 어떤 특징이 있는 것일까요? 그리고 학습 파라미터는 많을 수록 좋은 것일까요? 이번호에서는 LLaMA를 중심으로 대규모 언어 모델(LLM) 동향에 대해 알아봅니다.
|
|
|
2023년 LLM 트렌드 분석
PaLM
먼저 PaLM은 2022년 4월, 구글이 공개한 언어 모델입니다. PaLM의 학습 파라미터 규모는 GPT-3과 단순 비교해 약 3배 이상 큽니다(GPT-3: 175B(1,750억 개), PaLM: 540B). 학습 파라미터가 많다는 건 더 많은 것을 배우고 활용할 수 있다는 의미입니다. 먼저 PaLM은 영어와 다국적 언어 데이터셋으로 학습했는데, 여기에는 고품질 웹 문서와, 서적, 위키피디아, 대화, 심지어 GitHub 코드까지 포함되어 있습니다.
이렇게 많은 파라미터를 잘 소화할 수 있게끔 하는, 학습 최적화를 위해 새로운 방법이 필요했습니다. 바로 Pathways입니다. Pathways는 2021년 10월 구글이 공개한 멀티태스킹 AI 아키텍처로, PaLM이 여러 TPU(구글이 자체 개발한 머신러닝 특화 전문 칩)에 분산 처리되어 빠르게 학습할 수 있도록 하였습니다.
PaLM의 가장 큰 특징은 손실 없는 단어 사전(Lossless Vocabulary)을 만들었다는 것입니다. 통상 언어 모델 학습 과정에서는, 자연어를 전처리하고 단어 사전을 구축하는 과정에서 불필요한 정보(공백 문자, 특수 문자)들을 제거합니다. 학습에 활용될 단어 사전의 크기를 줄여야 더 적은 컴퓨팅 자원으로 학습할 수 있기 때문입니다. 하지만 이 때문에 글의 맥락이 완전히 달라질 수 있습니다. 특히 GitHub 코드 작성 환경에서는 탭(tab)과 띄어쓰기 등이 매우 정보를 담고 있기도 합니다. PaLM은 이런 정보를 언어 모델에 보존하기 위해, 공백 문자, 특수 문자 등을 단어 사전에 포함하였습니다. |
|
|
파라미터가 많아질수록 언어 모델에서 활용 가능한 하위 태스크가 많아짐 |
|
|
PaLM은 학습에 Transformer 모델을 활용합니다. Transformer의 Decoder 부분만을 활용하는데, 활성화 함수를 대체하거나(SwiGLU Activation), 일부 레이어(Parallel Layers)를 변형하여 대규모 처리에 최적화하였습니다.
주목할 만한 3가지 태스크는 언어 이해와 추론, 그리고 코드 생성입니다. 요약하면 다음과 같습니다.
-
언어 이해 태스크에서 비영어권 학습 데이터가 전체의 22%밖에 차지하지 않는데도, 다국어 벤치마크에서 뛰어난 성능을 보였다.
-
Chain-of-Thought Prompting 방식을 적용하여 9-12세 아이 수준의 추론 성능을 보였다.
-
다른 코드 생성 모델(OpenAI Codex)보다 코드 데이터가 약 50배 적은 수준(Codex는 100B, PaLM은 2.7B)이었음에도 동등한 성능을 보였다. 더욱 자세한 예시는 블로그를 참고하세요.
더 적은 데이터로, 다른 모델 대비 동등하거나 더 뛰어난 성능을 보였다는 것이죠. 연구진은 말합니다. 더 적은 데이터로 학습하였음에도 성능이 뛰어난 것은 더 ‘큰’ 모델로 학습했기 때문이라고요. 실제로 GPT-3 이후에 계속해서 더 많은 파라미터로 학습한 대규모 모델들이 등장했습니다. 하지만 과연 파라미터와 성능이 항상 비례할까요?
|
|
|
Chinchilla
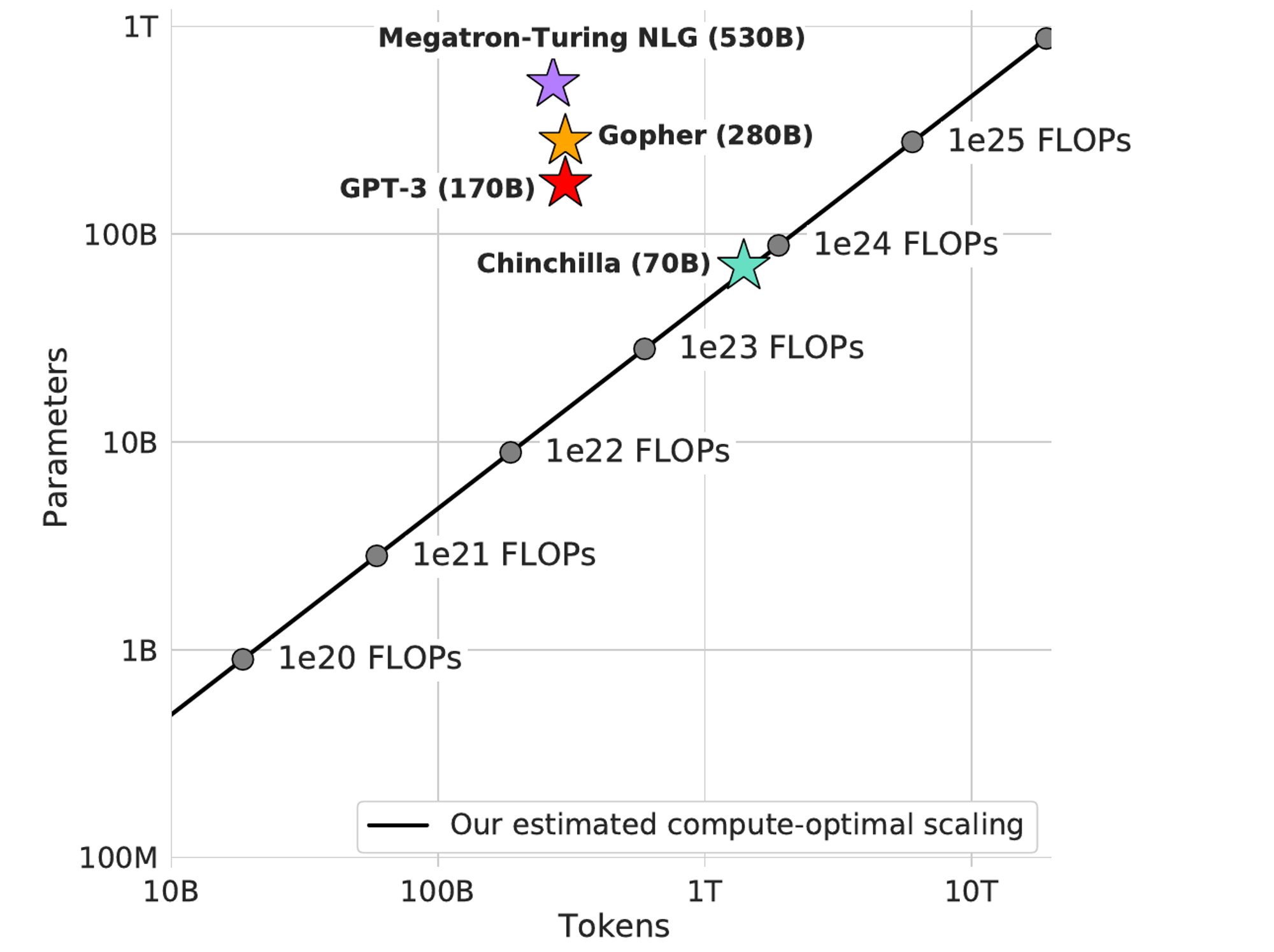
Chinchilla는 2022년 4월 DeepMind에서 공개한 언어 모델입니다. Chinchilla의 목표는 제한된 컴퓨팅 예산 속에서 최적의 모델과 데이터 사이즈를 찾는 것입니다. 딥마인드는 발표 당시 언어 모델이 크기를 키우는 데 집중하고 있는 반면, 그 크기에 걸맞는 학습 과정은 충분히 이루어지지 않았다고 지적합니다. 여기서 컴퓨팅 예산을 측정하는 단위로 FLOPs가 활용됐는데요, FLOPs는 FLoating point OPerations 즉, 부동소수점 연산이라고 하며 계산 가능한 횟수를 의미합니다.
학습에 필요한 컴퓨팅 리소스가 한정되어 있다면 그 리소스를 최대로 활용하기 위해 모델의 크기(파라미터)와 학습에 필요한 데이터 사이즈를 적절하게 조정해야 합니다. 그래서 Chinchilla는 파라미터와 데이터 사이즈의 트레이드 오프 관계를 연구합니다.
Chinchilla가 연구한 모델은 Gopher입니다. 2021년에 DeepMind가 개발한 언어 모델입니다. Gopher는 280B 파라미터를 활용했는데, 당시 SOTA 모델인 Megatron-Turing NLG(530B)에 필적할 만한 성능을 보였습니다. 하지만 Chinchilla는 Gopher와 동일한 컴퓨팅 예산으로 단 70B의 파라미터로 모델의 크기를 줄이고 1.3조 개의 토큰으로 데이터를 늘려 모든 분야에서 Gopher를 뛰어넘는 성능을 보였습니다. |
|
|
사실 PaLM과 Chinchilla는 거의 비슷한 시기에 등장했습니다. 계속해서 거대한 규모의 모델들이 공개되고, 실제로 그에 비례하는 좋은 성능을 보이면서 언어 모델 연구에서 사이즈를 키우는 일은 하나의 트렌드가 되었습니다. 누가 더 몸집이 큰 모델을 만드는지 경쟁하는 틈에 DeepMind 연구진은 최적화를 연구한 것입니다. 실제로 PaLM은 Chinchilla보다 성능이 더 뛰어납니다. 하지만, DeepMind 연구진은 구글이 PaLM을 연구하는 데 활용한 컴퓨팅 예산이라면 140B에 3조 개의 토큰으로 학습하는 것이 최적의 학습 방법이었을 것이라고 꼬집습니다. 작은 모델은 메모리와 추론 시간을 더 절약할 수 있어 더 효율적이기 떄문입니다.
참! Gopher와 Chinchilla는 모두 설치류에서 따온 이름인데 아시나요? |
|
|
LLaMA
이러한 흐름 속에 지난 2월 24일, Meta는 공식 블로그를 통해 새로운 언어 모델을 공개했습니다. 이름하여 LLaMA: Open and Efficient Foundation Language Models 입니다.
LLaMA도 PaLM과 마찬가지로 Transformer 모델의 Decoder를 기반으로 약간 수정하였습니다. 뿐만 아니라 Chinchilla와 마찬가지로 더 작은 모델로 더 많이 학습하여 성능을 높이는 데 초점을 맞췄습니다.
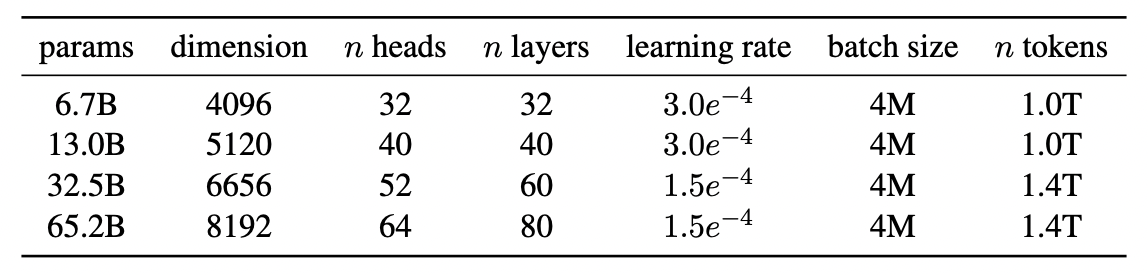
LLaMA의 특징은 다른 언어 모델에 비해 상대적으로 적은 파라미터로도 더 좋은 성능을 보인다는 것입니다. 연구진은 파라미터 수에 따라 총 4개의 모델로 나누었는데요, 가장 큰 모델이 65.2B로 앞서 소개한 Chinchilla보다도 작습니다. 하지만 대부분의 스크에서 PaLM을 넘어섰는데요, 심지어 절반 크기인 33B 모델이 Chinchilla를 넘어 PaLM에 필적하는 성능을 보였습니다. 가장 작은 모델인 6.7B는 GPT-3와 맞먹는 성능을 보입니다.
. |
|
|
PaLM이나 Gopher 같은 모델은 모델이 너무 커서 일반적인 연구 환경 인프라로는 감당할 수 없습니다. 하지만 앞서 말한 것처럼, 작은 모델은 재학습하거나 파인튜닝하는 데 훨씬 유리합니다. Meta는 LLaMA를 공개하면서 연구와 개발 커뮤니티에 도움을 주기 위해 개발했다고 말하며 코드까지 공개했습니다. Meta 연구진은 이와 더불어 LLaMA가 현재 AI계의 화두가 되고 있는 Responsible AI의 가이드라인을 만들어가는 데 도움이 될 것이라고 말합니다. Meta는 아직 언어 모델을 비롯한 생성 AI의 후발 주자지만 AI 커뮤니티에 기여함으로써 점점 입지를 넓혀갈 것으로 보입니다.
2022년 이후 등장한 언어 모델 PaLM, Chinchilla, LLaMA 대해 정리해보았습니다. GPT-3 이후로 시작된 LLM 시대는 더 크게, 더 많이로 요약할 수 있을 것 같습니다. 모델의 크기를 키우고 더 많은 데이터로 학습하면 좋은 성능이 나왔으니까요. 언어 모델의 성능이 포화 상태에 이르자 최적화와 경량화로 승부를 보기 시작했습니다. LLaMA는 정점에 와 있는 듯합니다.
하지만 한계는 분명합니다. 앞서 소개한 언어 모델은 모두 Transformer, 그 중에서도 Decoder 부분을 활용한 Autoregressive Transformer 기반의 모델입니다. 모델의 변화 없이 수 년째 컴퓨팅 능력과 데이터로 승부를 보고 있는 것입니다. 아마 언어 모델의 판도는 여기에서 달라질 듯합니다. Transformer가 2017년, BERT와 GPT가 2018년에 등장했다는 점을 미루어볼 때 새로운 트렌드로 전환되기 위해서는 2-3년 정도 더 시간이 필요하지 않을까 싶습니다. 물론, 그마저도 새로운 아키텍처가 등장한 다음이지만요. |
|
|
대한민국 최초,
피쳐스페이스(Feature Space) 기반으로 데이터셋의 분포를 눈으로 확인하고 데이터셋의 커버리지(Coverage)와 AI 모델 개선에 필요한 데이터를 보다 구체적으로 파악할 수 있는 데이터셋 분석 SAAS, DATUMO FST.
자유도 높은 분석과 큐레이션(Curation)을 통해 엣지 케이스(Edge case)를 분석하고 선별 알고리즘을 통해 엣지 케이스와 유사한 데이터를 조회하거나 전체 데이터셋을 대표하는 일부 데이터셋을 추출할 수도 있어 기존 기업의 AI 모델 성능 향상에 따르는 시간과 비용 절감에 혁신을 가져올 것입니다.
DATUMO FST는 현재 Free Trial로 제공 되고 있습니다.
DATUMO FST에 관심이 있거나 참여를 원하는 단체나, 기관, 기업은 아래 링크로 무료 체험을 부담없이 신청하셔서 AI DATA 분야에서 한걸음 앞서가는 얼리어답터가 되십시오.
|
|
|
154건의 성공 노하우가 보장하는 데이터 바우처 공급 기업,
대한민국 AI 데이터 선두 기업과 지금, 함께 하십시오!
3월8일 부산 센텀에서 현장설명회를 개최합니다
오셔서 막막함들 다 해소하시고 망설일 시간에
경쟁사들보다 먼저 신청하셔서
정부비용으로 부담없이 데이터작업을 진행하세요!
|
|
|
데이터라벨링도 최종 데이터셋의 품질이 중요합니다.
SAMSUNG, SK, LG 등 대기업을 비롯하여 ETRI, KAIST등의 국가기관과 연구소들과 셀수없이 많은 스타트업들이 결과물에 대한 확실한 만족으로
계속 이어가는 파트너십. 그것이 바로, 셀렉트스타의 독보적인 데이터 품질을 방증하고 있습니다. 거기다 세계적 AI 학회(NeurlPS, EMNLP, CVPR)에 논문이 모두 등재된 국내 유일의 데이터 플랫폼과 함께 귀사의 AI를 더욱 스마트하게 만드십시오!
DATA 수집,라벨링, 분석과 큐레이션까지
ALL in One AI DATA Solution, 셀렉트스타
|
|
|
AI 관심있는 누구나! 와서 노다지를 캐가세요!
- 직군, 나이에 상관없이 참여할 수 있는 오픈 모임입니다.
- AI와 AI 도입, AI 비즈니스, 사업개발에 대한 다양한 프로그램을 운영하고 있는 AI 중심의 커뮤니티입니다.
- 신사업팀, 사업개발팀, 변화혁신팀 등 회사 내에서 Digital Transformation을 위해 AI 도입을 고민하는 분들이 모여있는 곳입니다.
- 최신 정보와 기술, 작업 노하우, AI 모델 개발을 위한 플랫폼 서치, 전략 등에 대한 고민, 질문, 다양한 경험 등을 자유롭게 나누고 자기만의 값진 노다지를 캐가십시오!
|
|
|
Weekly AI Issues → →
AI가 만들어내는 ‘19금’
생성형 인공지능 모델이 상용화되면서 일반인들 사이에서도 사용 방법들이 공유되고 있습니다. 하지만 매번 좋은 방향으로만 활용되는 것은 아닌데요, 일부 이용자들은 음란물을 제작하는 데 활용하고 있어 논란이 되고 있습니다. 문제는 아직 이와 관련된 법률이 제대로 정립되지 않았다는 것입니다.
ChatGPT 열풍 NVIDIA는 웃고, 구글은 울었다
ChatGPT 열풍이 불면서 주식 시장에도 큰 변화가 일었습니다. AI 관련 기업의 주가들이 일제히 상승하기도 했는데요, 이중 큰 수혜를 얻은 기업과 오히려 역풍을 맞은 기업이 있습니다. NVIDIA는 AI 반도체 관련 산업 투자에 대한 기대감으로 크게 상승한 한편, 구글은 위기감을 느끼며 주가가 떨어졌습니다.
이미지 생성 AI, ControlNet
작년 7월, 텍스트 기반 이미지 생성 모델 Stable Diffuison이 인기를 끌었습니다. 그리고 더욱 진화한 ControlNet이 최근 주목 받고 있습니다. Stable Diffusion보다 어떤 점이 더 개선되었는지 영상으로 보실 수 있습니다.
AI TOP 100 논문 중 10건 중 7건은 미국산
AI 연구 동향을 분석하는 플랫폼 제타알파는 지난해 AI 관련 연구 중 피인용 건수 상위 100대 논문 중 68건이 미국에서 제출했다고 조사 결과를 발표했습니다. 단일 기관으로는 구글이 가장 많은 것으로 집계 되었습니다.
|
|
|
Join Us → →
지금
AI 데이터 업계에서
제일 밝게 빛나고 있는
셀렉트스타와
함께 하세요!
|
|
|
*이외, 셀렉트스타는
실무에 바로 활용할 수 있는
"오픈 데이터셋" 자료를
무료로 제공해드리고 있습니다.
홈페이지에서 신청해보세요
|
|
|
|
*본 콘텐츠는 deep daiv. 와의 제휴로 구성 되었습니다.
|
|
|
|
|